Salutations from the programming team! This is a big moment: the first technically oriented blog post we have ever had on the website. We thought we would discuss one of the more recently interesting and impressive systems – automatic lip-sync generation. As soon as we started development in Unity, we realised that with our proposed thousands of hours of dialogue and dozens of voice actors, manually importing and adjusting all audio to work in the game by hand was not feasible. Programming Lead, Hamish Milne, spent quite some time developing an automated solution. Down below you can see what he came up with!
Some technical talk follows! If you’re not into that and just want to get to the result, scroll down to find a download link (!) to a live demonstration that you can play around with.
But first, how exactly does one change a character’s facial expressions? Unlike normal animations, faces don’t have any skeleton or bones. Instead, "blend shapes" are used. A mesh is created for the extreme of each possible facial expression, and in our project we have a lot: smirk, frown, grin, pucker, lip raise, angry eye, closed eye, relaxed eye, sad eye, left side versions of the above, and more. Combined, we have thirty-three unique expressions in total.

Once we have these, we can combine them together in various configurations to create full facial expressions like happy or angry.


Yeah...How about no.
However, for lip-syncing, we need to create “visemes” – basic mouth and tongue shapes that we make when we speak. Fortunately, this is a much smaller set than the set of “phonemes”, which are the audible sounds. Whereas english has 44 phonemes, we only require 10 visemes, making things much easier for us as you will see.

Now that we have our visemes, all we need is to join them together to make it look like the ponies are talking! Unfortunately, this is the harder part. Extracting phonemes from audio data is a tricky business, but luckily a library already exists for C# and the .NET framework, the Microsoft Speech API. This makes getting text out of an audio file a doddle.
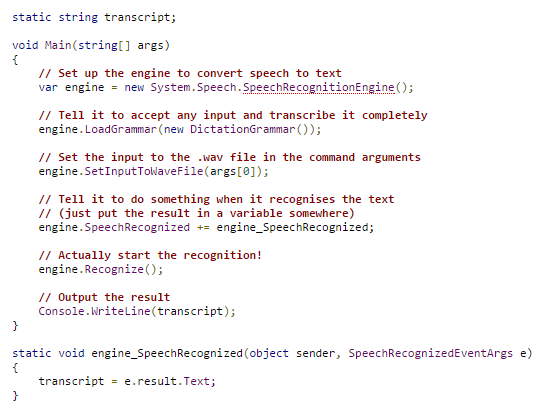
Let’s test it out and see what text it gives us from one of our VA lines. The transcription should be: “you make a real bad conversationalist, you know that?”

Okay, not as accurate as we hoped for. No wonder those auto-captions for Youtube never work. However, we don’t want the text, we want the visemes. Let’s see what the pronunciation property (of each word) gives us:

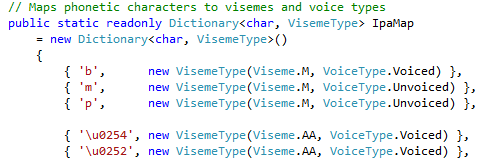
A little better. This is the interpreted text in IPA – the International Phonetic Alphabet. Each of these funny symbols represents a discrete sound, and of course, every sound has an appropriate viseme. Eagle eyed readers might notice that “kama” word in the middle, a transcription of the “comma” in the text, which would seem to be out of place. This confused me at first until I said it out loud: “roebuck comma socialist”. Sounds a bit like “real bad conversationalist”, doesn’t it? The engine obviously thought the line contained the word “comma”, and transcribed it as such. Anyway, I used the chart above, plus a helpful wikipedia page to make a map of IPA characters to visemes.
Great! We now have a list of visemes for the audio. The best part is that reducing the number of symbols from 44 to 10, we massively decrease the chance of visible errors. As we’ve seen, even if the speech recogniser gets the transcription all wrong, the list of visemes should still be fairly accurate.
The final step is to position the phonemes within each word since the speech library doesn’t give us this data, only the position of the word in the whole line. However, we can use a fairly simple rule for the length of each of them, 30ms for a consonant, 50ms for a short vowel, and 60ms for a diphthong. Then we just scale those numbers up or down to match the real length of the word.
There were a few other problems, most notably that Mono (the open-source implementation of the .NET framework) is for some reason unable to access the speech library. To use the program from Unity (which uses Mono) I needed to create a separate process and transfer the data using base64. There’s a couple of implications here: firstly, the program will only work on Windows, and only with an english locale. It’s possible to change it, but it’s a bit of a palaver. If anyone finds a way to get it to work with a non-english locale, contact us right away with the subject line: “You Wasted Five Hours on a Problem I Fixed for You”.
(Note: This does not mean that the final game won’t be multiplatform. This is only an issue during development. The finished product will have the lipsync output pre-baked into the game data so anyone can play it.)
The finished utility is available here, in source code and binary for you to look at, experiment with, and use in your own projects.
Important Legal: The utility is licenced under GNU General Public License (https://www.gnu.org/licenses/gpl.txt) By Hamish Milne & The Overmare Studios.
But of course, what you really want is to see it in action. That’s why we’ve made our lipsync demo, that you may have seen at Czequestria, available for everyone to download and play with. Before anyone asks, the Unity Web Player is incredibly restrictive to what sort of code it allows, so no, unfortunately, we are not able to use that.
Important: Since the speech recognition is done with the Microsoft Speech API, it requires an English version of Windows to work. Regrettably, this means that if your OS has been installed with a different language, it might not work for you due to the lack of a compatible recognition engine. Notably, the Finnish language doesn't work at all, but the German language seems to manage fine. Leave a comment to let us know if your experience is any different.
Download the demo, here.
Instructions:
Simply select an audio input, then use the appropriately labelled button to start and stop recording. You can then playback the audio with lip-sync on any of the available characters.
You’ll also see a box labelled “Mood”. You can type in moods here and press “Set”. They’ll be applied to the current character. If you wish, you can apply multiple moods in a comma-separated list, and even give each mood a value by typing “=”, followed by a number between 0 and 1 (the default being 0.5). Here are all the moods we currently have:
- Happy
- Sad
- Angry
- Furious
- Laugh
- Curious
- Scared
- Confused
- Embarrassed
- Excited
- Stubborn
- Confident
- Shocked
- Bored
Rather than using the microphone, you can also import audio from (most) WAV files. Simply type in the path to the file (relative to the program’s directory, including the extension) and press “import” instead of using the record function.
Finally, you can set a transcript. This will instruct the engine to match the input speech to the audio, rather than guessing what the audio contains. This can sometimes improve the final result.